Clinicians on FHIR, Pareto and the Clinical Unknown
📅 21 November, 2017
•⏱️5 min read
I spent an enlightening day at the Clinicans on FHIR event at the King's Fund on November 21. It was good to get a pure FHIR perspective with a group of people who were there to learn about the technology. Although one particularly savvy chap did ask the question about the FHIR hype cycle, the presenter, David Hay admittedly avoided giving a detailed answer. But did add that FHIR advocates feel a responsibility to to dampen down some of the noise that suggests the interoperability technology is answer to all ails.
Much of the discussion from the morning's session was confined to interoperability, or the definition of it. I raised the issue on the difference between semantic interoperability and technical interoperability by way of question to David, and queried where the limits of FHIR are defined. The general message back is that "we'll see where this goes", but it was clear that semantic interoperability is not what FHIR was initially designed for, and David acknowledged that. This is an important statement as it should ground some suppliers from within the community that feed this hype cycle.
Take the replacement of HL7 V2 for example: there are vendors who are advertising selling FHIR as a solution for legacy V2 messaging but the message from the pulpit today was essentially "if it ain't broke, don't fix it". HL7 V2 will be around for some time to come alongside V3/CDA if you have a working instance of it.
Another example concerns the persistence of FHIR as a repository in its' own right. Again, the technology represents a technical interoperability solution and was not defined for storage but at some point when you have several resources all in one place, it becomes a data repository in of itself. I can see this makes complete sense within the confines of an implementation of a specific set of use cases. However, this is not covered by the FHIR specification which offers no view on data persistence, and I believe can be confusingly conflated with the 80% rule that is liberally applied to the extent of FHIR resources.
For those who have not gone through the Service Improvement ringer, Joseph Juran's Pareto Principle states that "80 percent of consequences stem from 20 percent of causes" and it's been a valuable tool for me in the past. There's nothing I like more than a good Pareto Chart...
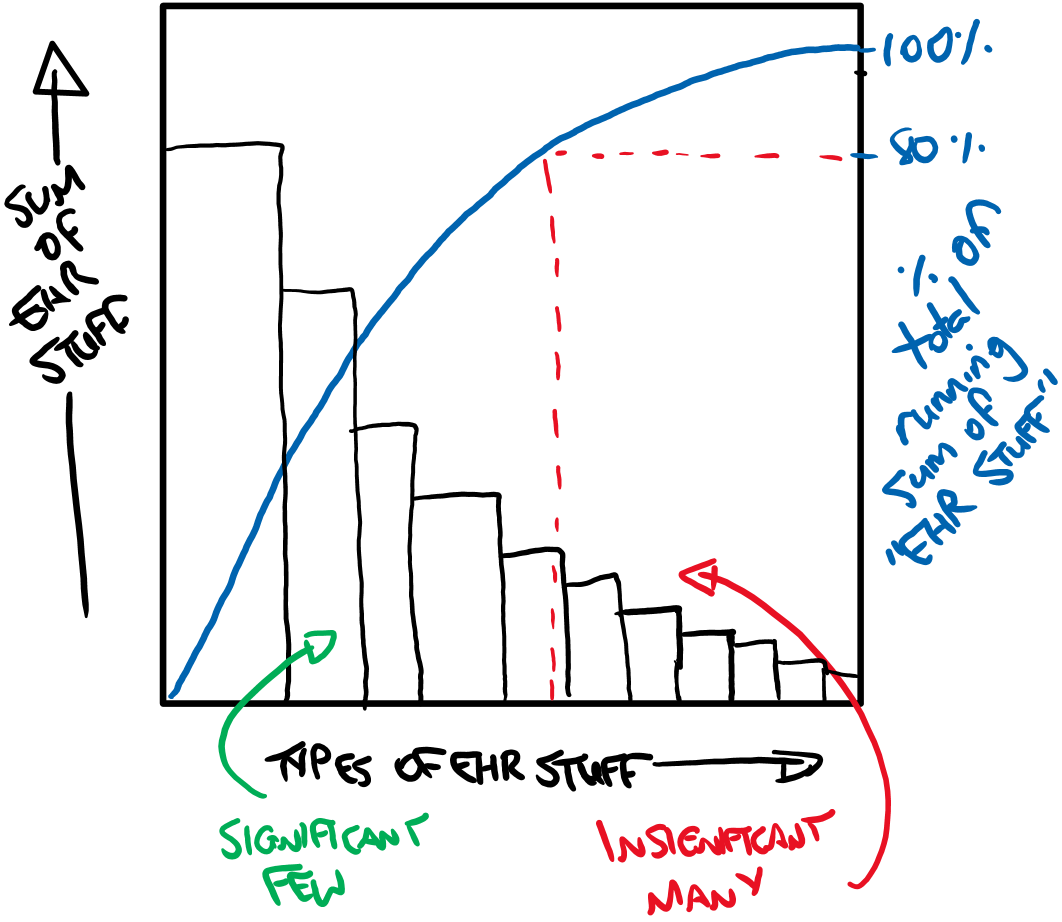
The above scribble basically pits the different EHR categories such as admission data, pathology or billing against a sum calculation of the scale of these categories (i.e. lots of fields added together). The theory would play out that 20% of the "EHR Stuff" will account for 80% of the data to be recorded. Essentially it's low hanging fruit for a vendor and is a sensible start point for a specification of a range of resources for EHRs to consume.
The issue I take from this (and it has yet to be stated for definite) is whether a full Pareto analysis was conducting when specifying the FHIR resource requirements. I doubt it was and this is a problem as the 80% of fields in incumbent e-hospital systems tend to be the big ticket clinical domains of radiology and pathology, or administrative and billing. There's little space for the granular clinical data items that may be peculiar to specific clinical specialties. Therefore there is a long tail of small data items. However, this is clinical data and the insignificant many could actually be pretty important. Which has led me to think that maybe there is a hidden tail to the "Types of EHR Stuff" axis akin to this:
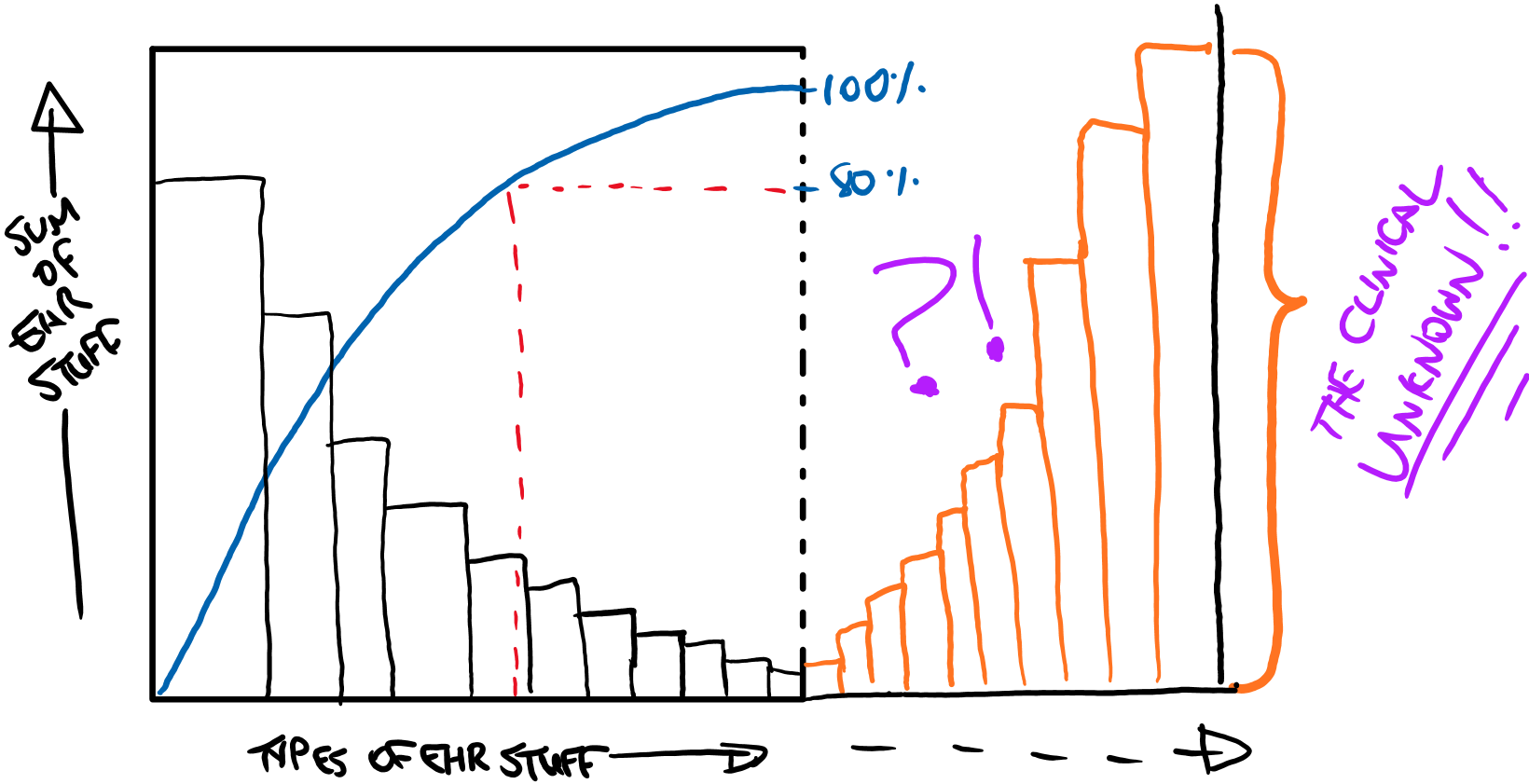
Let us not forget that if 20% of the EHR "causative stuff" still leaves 80% of other things. In reality it is probably not an 80/20 split but this is all very confusing nonetheless.
As someone looking to design and build a national diabetes platform, the Clinical Unknown scares me. I have no doubt that the FHIR specification can accommodate this - it is designed to. But the scale of work required to ensure that this is computable in accordance with a solid information model is significant without an archetype-esque construct underpinning it. I thought it interesting to hear David Hay mention that embedding openEHR archetypes into FHIR was something being considered, and adds weight to the theory.
My fear is that in the real world, corners would be cut to ensure that work gets done on time. If the only way to query a FHIR repository is to ensure shared coded entries (i.e. Snomed) are saved in each record we could find ourselves in a world where the compliance specification for each method is significant. And then what happens if we change from Snomed to something else? Those mandated codes could become obsolete without an additional transformation occurring somewhere in the process.
And here lies the dichotomy of FHIR: it is an admittedly open standard but only at the information exchange layer. As soon as that is persisted, it ceases to be vendor neutral as there is no specification or requirement to store FHIR based data in an open way. It simply wasn't designed to do some of the things people say it can.
As far as I am aware, none of the FHIR based repositories such as Vonk are vendor neutral. And despite offering FHIR based services, the likes of Epic and Cerner are definitely not vendor neutral. I nearly spat out my coffee when I found the Open Epic website, but kudos to the marketing guys for jumping on the "open" band wagon.
So whether you should persist a FHIR repository comes down to your specific needs. It makes a compelling case for implementors (i.e. FHIR's target audience) building components of an EHR, but to underpin the entire health record itself? That is an order of magnitude more difficult.
Coming full circle to the Clinican's On FHIR event, it managed to focus my mind on what FHIR can and cannot do. If I were to be critical, I believe that the message (no pun intended) got lost during the day as the agenda tried to skirt around the technical nature of the technology. Some of this stuff is hard to understand as it is inherently technical, and the clinical audience genuinely got confused at several points as the objective of what we were creating seemed vague. But the message does need to get through to ensure that the hype cycle phase of "unrealistic expectations" does not continue and we can crack on with letting FHIR help us with the technical interoperability challenges it was built for.