
Setting Up openEHR in Azure II: This Time It's Painful
📅 06 May, 2020
•⏱️9 min read
A while ago I set about learning how to spin up openEHR on cloud services. While the path to persistent data did not run smooth, it got there in the end with a successful deployment of the open source CDR, EtherCIS. With the advent of a new CDR, EHRBase, I thought I would try it again. This post gives both an update to on how Microsoft's Azure offering for containers has evolved over the past couple of years, and what the Child of EtherCIS offers the openEHR community. Unfortunately the following makes not nice reading for Azure fans...
What is EHRBase?
For this example, I'm looking at the new shiny shiny called EHRBase. This is the spiritual successor to EtherCIS. It is an open source and openEHR standards complaint clinical data repository developed by Vitasystem, Germany. It's also (at the time of writing) very much a work in progress but if you keep an eye on the github repository you will see a steady stream of updates. I initially started working with EHRBase from the self-contained Docker image on my laptop. It's spins up very neatly based on the Docker images and I would encourage anyone interested to do this first to gain experience in a more considered environment.
The principle EHRBase issues (from my perspective) in terms fitness for enterprise deployment surround some of the file formats used in messages as it relies on the canonical XML and JSON formats. This is a core part of the openEHR specification but from a test/dev perspective is somewhat smelly and gives me a headache. Anyone that has used the Better flat or structured JSON formats immediately notices the voluminous addition of detailed archetype data that the canonical format contains. However, this is one of the strong points of openEHR as a canonical composition can be read by ANY openEHR CDR and is part of the specification. I am not saying this is in any way wrong, just different.
There were some other interesting things I encountered such as you cannot update an operational template, but no sooner than I had raised it, those clever people fixed it. But I reiterate, is is more than good enough to allow you to get off the ground with openEHR which is why it was so important to get this spun up in the cloud for all to tinker with.
Problems...
I'm not going to go through every step that I have taken over the past couple of months trying to get this to work, but will provide a precis version that concerns the Microsoft interpretation of how containerised applications should work in Azure. Also, this is not to be confused with the Kubernetes service. I have a colleague who has dabbled with that (and had success) so it remains that Azure may be/should be an option for scalable deployments of EHRBase in future.
While it should be possible in theory to run the docker compose file found here, there are a few points to mention. The Docker Compose file has two distinct services for the application (ehrbase) and the Postgres database (ehrdb).
version: '3'
services:
ehrbase:
image: ehrbaseorg/ehrbase:next
ports:
- 8080:8080
networks:
- ehrbase-net
environment:
DB_URL: jdbc:postgresql://ehrdb:5432/ehrbase
DB_USER: ehrbase
DB_PASS: ehrbase
AUTH_TYPE: BASIC
AUTH_USER: ehrbase-user
AUTH_PASSWORD: SuperSecretPassword
SYSTEM_NAME: local.ehrbase.org
restart: on-failure
ehrdb:
image: ehrbaseorg/ehrbase-postgres:latest
ports:
- 5432:5432
networks:
- ehrbase-net
volumes:
- ./.pgdata:/var/lib/postgresql/data
environment:
POSTGRES_USER: postgres
POSTGRES_PASSWORD: postgres
EHRBASE_USER: ehrbase
EHRBASE_PASSWORD: ehrbase
networks:
ehrbase-net: {}You need both of these to be able to communicate with the CDR, and persist the data held within.
Azure Web Apps
Microsoft have several different container products available and understanding the difference between them is important. Web Apps are a service for self-contained apps (go figure?!) that are fully managed. But there is significantly less configuration available when compared with Azure Container Instances (ACI). Web Apps also only enable access on publicly available HTTP/HTTPS ports which I found was a problem for accessing the PostgreSQL database.
I look at the differences between both offerings as one of simplicity; if you intend to deploy a multicomponent application you may be better with ACI owing to the greater control available for configuration.
As it seemed so easy to spin up EHRBase locally, I assumed the same would apply to the Web App container (that was mistake Number 1). What I immediately noticed was that data committed to EHRBase was not being persisted when the container is taken down or restarted. I do not have unlimited Azure credits to keep services running but even in an R&D capacity persistence is very useful.
I contacted Azure support who informed me that the lack of persistence is by design. And I can see there are good uses for this, however, it does make things more complex which is the opposite of what I was intending to do.
In problem solving mode, I used the docker compose as the basis for a Web App resource, importing the YAML file via the Azure UI;
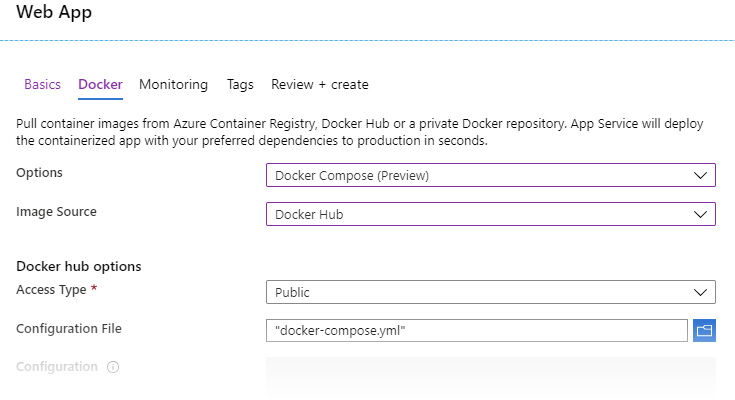
While this appears to deploy correctly with no errors, the route to exposing the correct ports to enable API access was less clear. Firewall config is wide open as standard so there is nothing I should have needed to change. In short, I could not get it to work.
Azure Container Servitude
At this point I swapped over to Azure Container Services to give me a little more control over how the containers would deploy. I ran through the options, first running the vanilla YAML, then splitting the containers out as separate instances. The persistence issue once again became a problem and I initiated a longer dialogue with support, aiming to do it the Microsoft way and playing ball.
Several docs were thrown at me, which confused as much as enlightened. I am not the most well versed in Azure so Googling for solutions to persist data found out of date posts relating to Azure Blob storage. This is now deprecated in favour of File Storage.
The process amounted to the following;
- Create separate File Storage Account
- Create a link within the docker compose YAML
- Use the YAML as configuration template within ACS
What didn't help was a lack of understanding with the Azure support. I should have said up front that I have no access to change the path to the Postgres db folder within the container itself. Even after I successfully attached the storage account, EHRBase itself didn't know what to do with it as it was trying to write to ./.pgdata:/var/lib/postgresql/data which would not persist. My mounted share was always empty. I realised then that I needed to mount the file storage to this path (which seems pretty obvious in hindsight).

At this point, the nail got hammered into the coffin: the container would hang at each point when it tried to initialise the Postgres database:
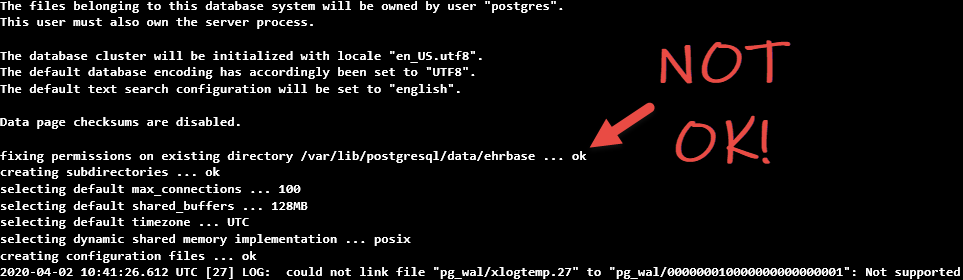
What is happening is that the shared folder is being correctly found, and the EHRbase image tries to change permissions to have full write access. The Azure File Store appears to return a digital thumbs up other container and so EHRBase continues along its merry way. Until it tries to write something to the folder.
I was getting frustrated at this point but was not alone. I found a GitHub page which detailed a fundamental incompatability with Linux file systems on Azure;
The only other way this can be fixed is by attaching a volume to your VM, formatted in one of the linux filesystems (eg. ext4). I also think docker will not be able to take care of such issues. Its basically a windows / linux interoperability issue.
To my mind, Microsoft have here forced the splitting of persisted data and introduced a far more significant issue which amounts to not supporting Linux containers correctly. How this can be marketed as a cloud solution is beyond me. Azure containers should offer persistence as an option and not force developers down this arduous route.
The Azure support tech did try working through this problem including running privileged containers. This is currently a feature request but does not help at the moment.
Going Solo
The next suggestion was to set up a separate PostgreSQL database instance in Azure however this was not exactly straight forward either as only certain extensions are supported by Azure. EHRBase requires temporal tables and JSQuery, and while Team EHRBase mentioned these were not mandatory, I could not help but feel not using them would be counter intuitive.
So at this point I had figured out that;
- Web apps don't work.
- Azure Container Services don't work.
- Dedicated PostgreSQL resource with the combination of an altered Application YAML file in 1 or 2, above did also not work.

The Workaround
The simple way to avoid these issues if you are Hell bent on getting EHRBase into Azure is to spin up a Windows or Linux virtual machine and launch the container from within there.
Yeah. I know.
In order to launch a container, you need another computer to put the container in. Which you access from your own computer. I really thought I was missing the point of Cloud based infrastructure at this point... but it speaks more to the maturity of the Azure docker compatibility. Cloud based Linux or Windows Server seem the only options at this point, and to be fair that is what I have working at the moment.
Thoughts...
It makes a mockery of Docker that Microsoft cannot support Linux file formats but there we go. Somewhere along the line the decision was made to remove the ability to persist data within a container which is the principle problem detailed here. I admit that there are some good reasons to do this, as separating the data persistence from the application can compartmentalise testing, reducing the lead time and overall complexity. But that is of principal concern for production environments.
A "single source of truth" approach persists temporally based clinical data for use by multiple actors. We have to remember (and potentially readdress some definitions) that an openEHR system is the data, and applications are its' consumers. However, the service layer is integral to that persistence model and it seems perfectly acceptable to wish to persist the entire Docker image of EHRBase accordingly (i.e. Postgres and the APIs).
The lack of Cloud capability has not hindered my testing of EHRBase to the extent that I believe it is rapidly becoming a viable candidate for those seeking an open source implementation of openEHR. The pace of change is significant, and I hope to write up some of my other findings in due course.
The wider issue is that Azure is not all it appears to be. The difference between now and the work I did with EtherCIS two years ago is significant and the product has changed dramatically. Where will this be in another two years and is Microsoft making this up as it goes along? By giving out $150 in Azure credits to everyone, I get the distinct impression that Microsoft is cultivating an approach to “Cloud the Microsoft Way”. While this might make sense from a business perspective, it doesn’t exactly help me in creating cloud hosted test harnesses for applications within a community that is pretty much “not Windows stuff” inclined.
So, Amazon. Are you any better? 😉
I'd like to thank Paul Bargewell and Stuart J Mackintosh from OpusVL for their support as I started to rip my hair out during the above "learning experience". Sage advice as always.